This article
For a while now, I've been helping Axonerve, a startup that is developing its own FPGA-based key search engine. Now that we have a prototype version of the Redis Server using the Axonerve engine, I compared it to the common software-based Redis Server.
We confirmed:
- In terms of throughput, our system scales linearly up to 75M requests/sec.
- In terms of latency, it runs at 3 microseconds constantly.
If you want to see the results first, please skip to Axonerve Server (with TestCenter). After that, you can come back later and check out the details.
Note that the same software is available on the Xilinx App Store and is ready to try. The FPGA card described below is required, but without it, you can still check out the software and other features.
Axonerve
Axonerve is a startup developing its own FPGA-based key search engine. To achieve high performance and low latency, the key and value are both stored in memory on the FPGA.
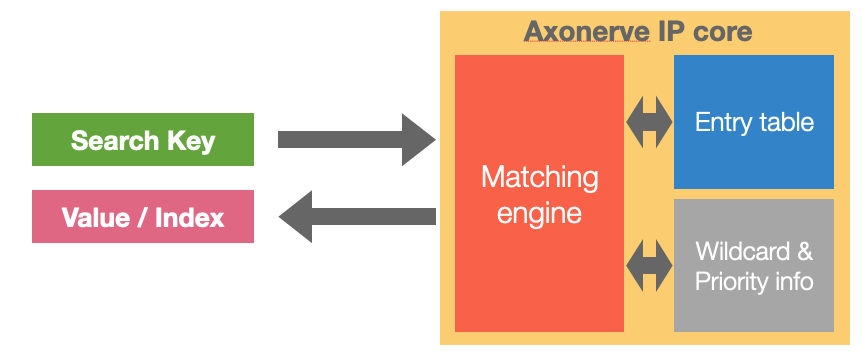
The following is a brief list of performance-related information.
- Key length: 144 / 288 / 576 / 1152 bits
- Maximum entries: 1 Million
- Latency: 120 nano seconds (constant)
- Throughput: 150 MSPS(*1) (in 150MHz clock)
In addition, it not only matches exactly to the key, but also allows wildcards such as "if this field is this, then the other bits can be anything". If you are familiar with OpenFlow's match patterns, it is easy to imagine. See the web for details.
This test was carried out on a version of Axonerve that uses HBM to expand the number of entries. The key length is 288 bits, the number of entries is 64M, and the latency is 600 nanoseconds. Think of it as the development of an ultra-fast Redis server that can register 64 million 36-byte String keys.
*1) In this paper, the capability of the FPGA as a key search engine is expressed in terms of MSPS - Million Searches Per Second, which is often used to describe the processing power of TCAM. Meanwhile, to describe the processing power as a Redis Server, we use M RPS - Million Requests Per Second, which is more familiar to people in this field.
Measurement environment
We run a test with the following equipments.
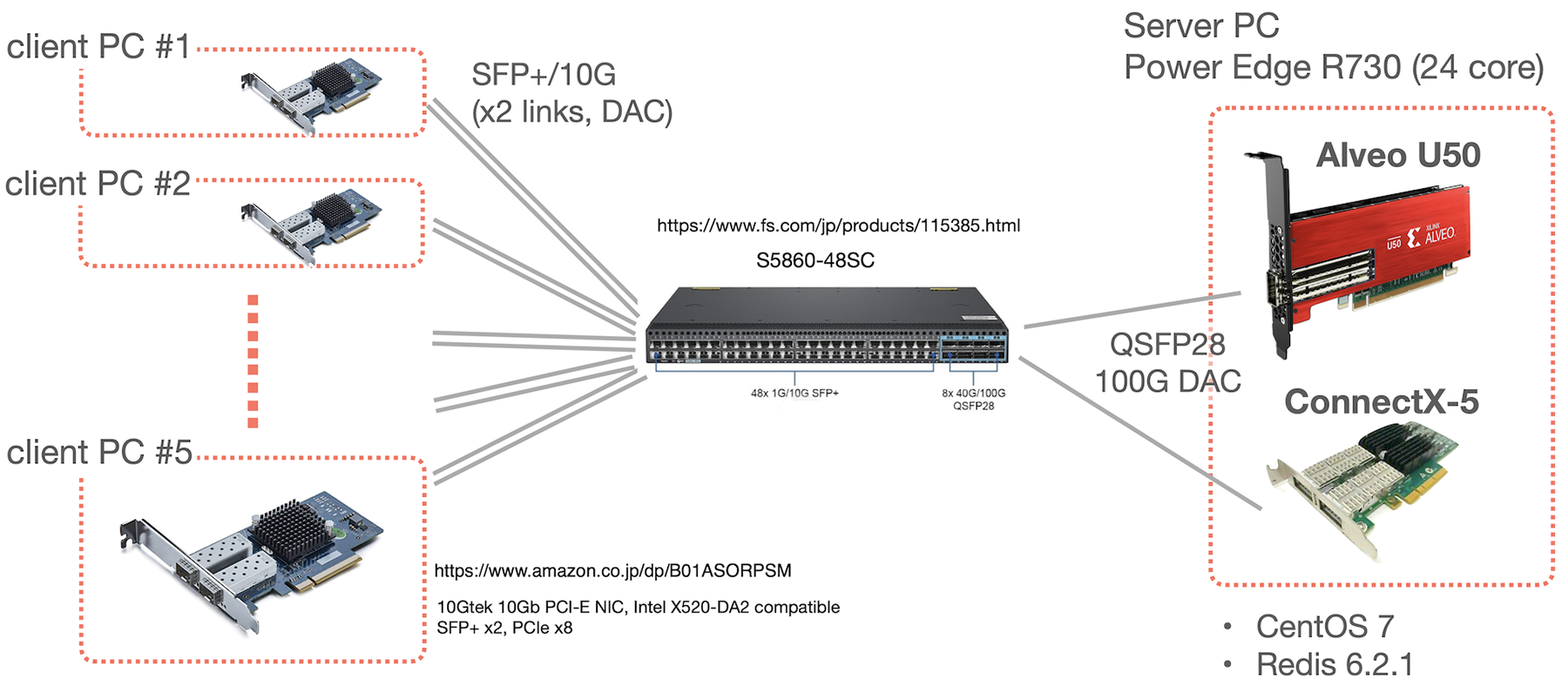
Multiple client PCs can use redis-benchmark to compare the throughput and latency of the Axonerve Redis Server on FPGA (hereafter called "Axonerve Server") and the Redis Server on an ordinary Linux host (hereafter called "Software Server").
Axonerve Server
Axonerve Server runs on Xilinx's Alveo U50 FPGA card, and processing requests such as SET/GET are completed within the FPGA card, with no interaction from the host PC. The U50 has a 100G Ethernet interface on the card, and Redis requests are performed through this interface.
Software Server / Server PC
For a comparison, the Software Server is running on a PC that is also the host of Alveo. This PC is equipped with a 100G Ethernet card (Mellanox ConnectX-5) and Redis requests to the Software Server are processed through the ConnectX-5.
The model is DELL PowerEdge R730. Here's information related to performance.
- Xeon E5-2650 v4 (12 cores, 2.2GHz) x2
- CentOS 7
- Redis version 6.2.1
- AOF, RDB are both disable (No persistence)
- io-threads is 7, io-threads-do-reads is NO (The optimal value experimentally obtained)
(When AOF/RDB is enabled, io-threads 15 was the optimal value)
Client PC / Network
We use the redis-benchmark for the measurement. This tool has several configurable parameters for multiplexing, such as number of connections and threads. In the following sections, you will see the throughput (requests/sec) and average latency for Axonerve Server and Software Server, respectively, and these numbers are based on the best settings of multiplicity for each environment. Note that pipeline processing has not been set.
As client PCs to run the redis-benchmark, we prepared five NEC Express5800/T110j-S (N8100-2798Y). All of them are equipped with 10G SFP+ x2 NICs. These PCs and the 100G server are connected through FS.com's S5860-48SC switch. It is configured as a simple L2 switch.
Notice (1):
Axonerve Server is not configured to support TCP at the moment of the test, so we modified the redis-benchmark to send and receive dedicated L2-level packets over raw sockets. In this sense, please note that this is not a fully fair comparison.
Axonerve has implemented this prototype version to make sure that the basic performance is sufficiently high, rather than testing under completely identical conditions. If you are interested in the details of the internals of this part, please see the information on the Xlinx App Store.
Measurement result: Throughput
Here are some results that illustrate the features of Axonerve Server to help you understand it more.
Software Server (with redis-benchmark)
First, as a baseline, let's take a look at the results of the SET/GET throughput of the Software Server when the number of redis-benchmark clients is increased.
$ redis-benchmark -t get -c 64 -n 100000 --threads 64 ...
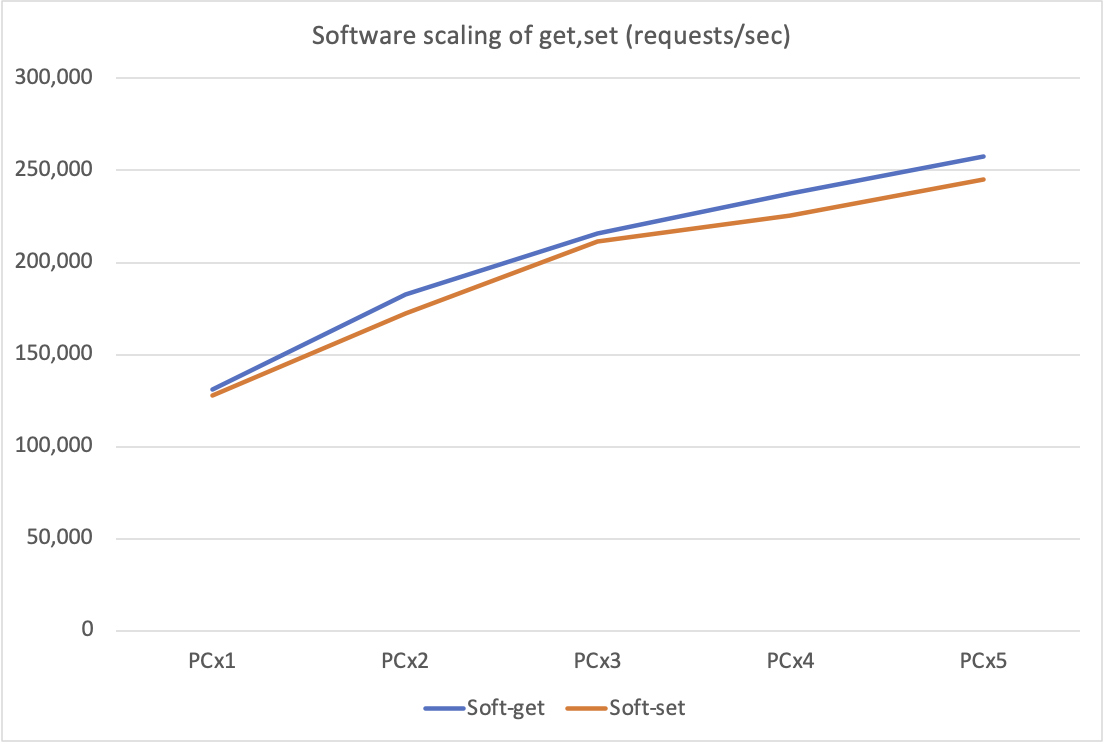
The horizontal axis is the number of clients. The vertical axis is requests/sec. You can see that the number of requests increases as the number of units goes up. Note the angle is gradually getting down. An approximation line is shown below as an assistance.
When we increased the number of clients, the growth rate slowed down. It is not clear why there was little change in adding PC#5 when you have client 4 PCs. However, at this time, the server CPU utilization (*2) reached 40% for one PC and 55% for five PCs. If we use a higher performance server or increase the number of the clients further, the total throughput will be still higher. However, at about twice this level, in any case, it seems to be stalled.
*2) Average value of main thread and 7 io-threads as indicated by top -H. As for io-threads, as mentioned earlier, it is confirmed that the overall throughput does not increase if the number of threads is increased further.
Notice (2):
The purpose of this test is not to achieve "the world's fastest single Redis server performance". The main purpose of this test is to confirm the performance of the Software Server at hand and the adequacy of this experimental environment, and to see the curve, or trend, when the load is scaled. Please keep that in mind while reading the rest of this chapter.
In terms of a maximum number of requests, there are cases where SET/GET can handle up to 500,000 requests/second, twice as many as our environment. See this article (sorry for the Japanese!) for more details. If we do it now, we may be able to get even higher numbers.
Axonerve Server (with redis-benchmark)
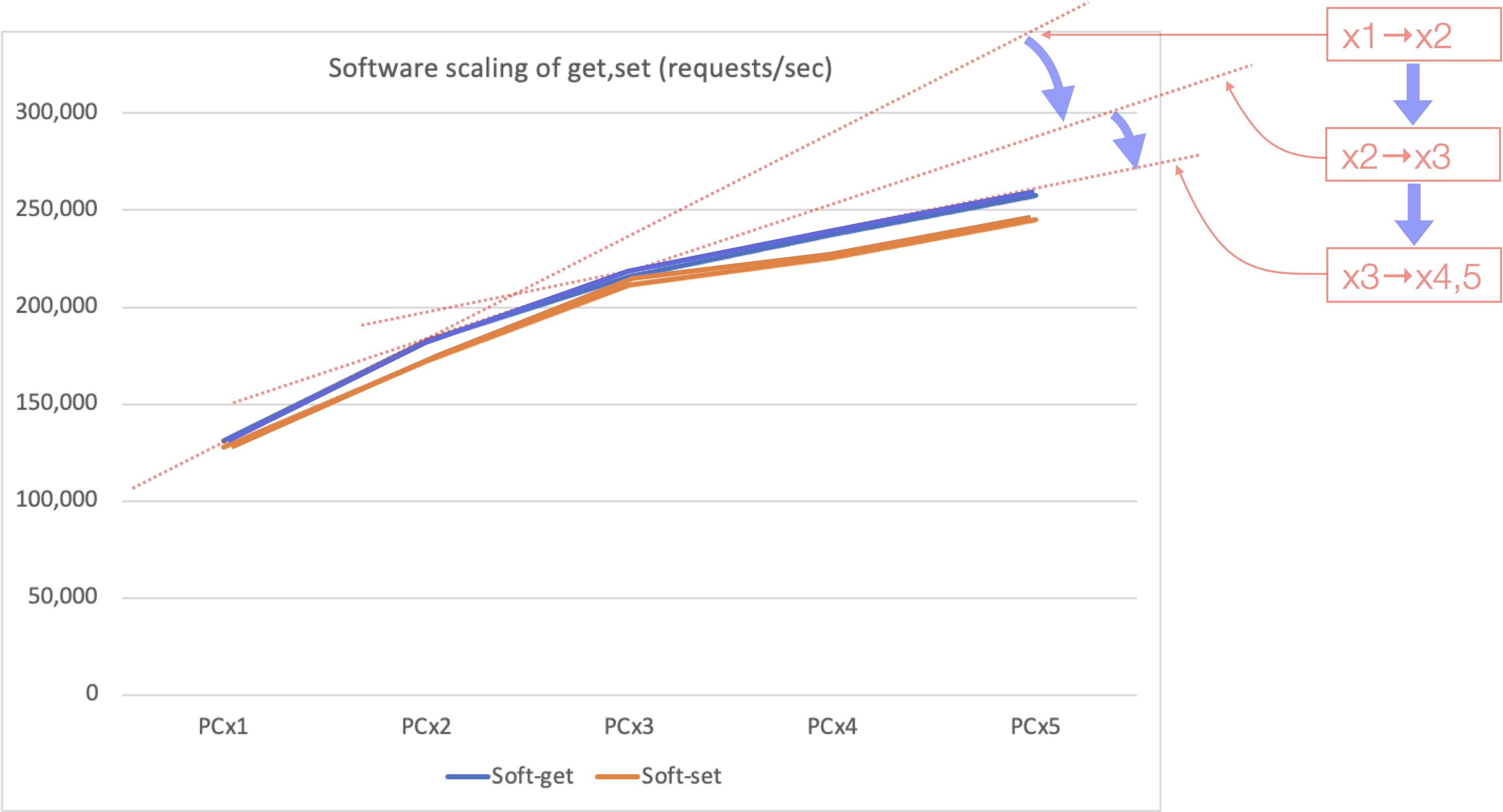
Now, take a look at the difference in the SET/GET throughput of the Axonerve Server as we increase the number of redis-benchmark clients, by adding it to the Software Server graph above.
$ redis-benchmark -t get -c 64 -n 4000000 --threads 64 ...
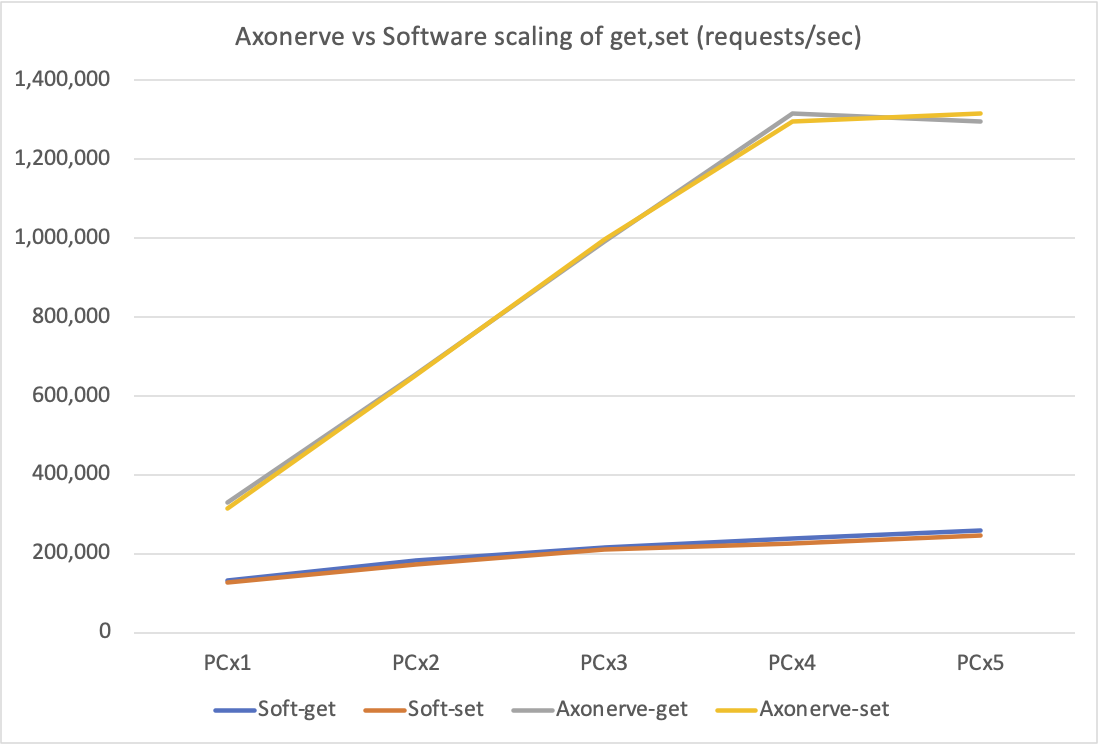
The added gray and yellow lines are the results for Axonerve Server. The client environment is the same as in the Software Server test above (except that the lower layer of the redis-benchmark software is different, as shown in Notice (1)).
With a single client, the throughput is double of the Software Server, but it is more noticeable that the angle is almost 45 degrees, and it scales perfectly linear up to four clients. This means that there is no need for us to work hard to prepare a Software Server with "double" performance.
On the other hand, the sudden lack of growth when the number of clients increased from 4 to 5 could be a concern, but the next test will show you that it is not a problem with the Axonerve Server itself.
Axonerve Server (with TestCenter)
As there is a limit to increase the load with 5 client PCs, so we used Spirent TestCenter (*3) to create and send request packets.
*3) Network load testing device. It measures processing speed by generating arbitrary packets and sending them out at specified intervals. In this test, it is connected to the switch mentioned above with 10G line x10.
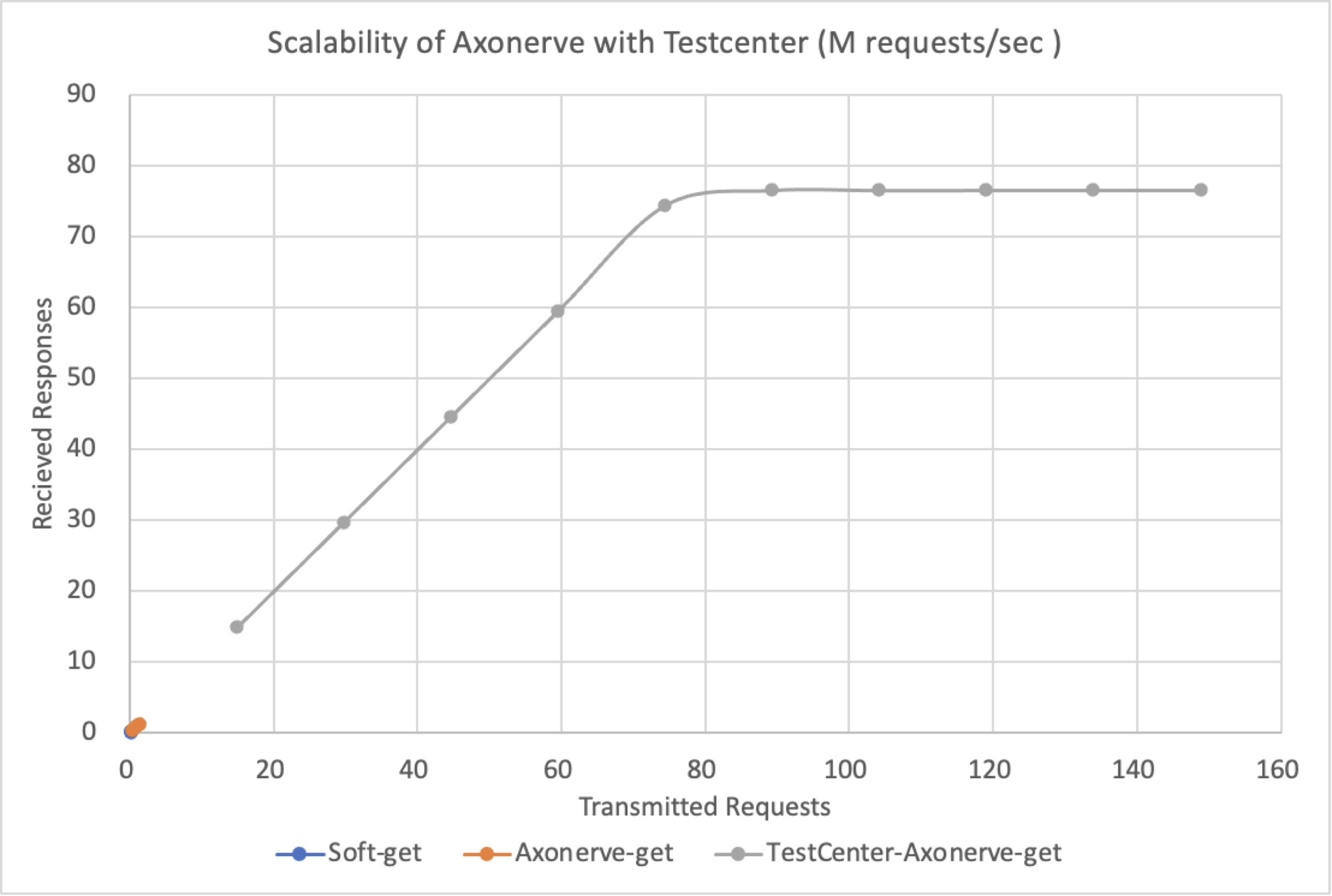
The horizontal axis is the number of GETs sent out, and the vertical axis is the number of responses received. The units for both are Million Requests Per Second (M RPS). Just like the previous test, the response performance to the amount of requests increases linearly up to 75M RPS with a perfect 45 degree.
What is remarkable is the lower left corner of the graph, near the origin. The short blue and orange lines in the lower left corner are the redis benchmark results graphs for the Software/Axonerve Server (corresponding to the area shown above). In other words, the maximum value we got running the redis benchmark on 5 PCs was about 250,000 (=0.25M) RPS for the Software server, and about 1.3 million (=1.3M) RPS for the Axonerve Server.
This means that if you can send requests, it will respond linearly up to 75M RPS, an order of magnitude higher.
The reason why the upper limit of transmission 150M RPS is, because that is the wire rate of 100G Ethernet. The clock cycle of the FPGA in the Alveo U50 is also 150 MHz, and the maximum performance of the Axonerve IP core is 150 MSPS (Million Searches Per Second). In the current implementation of Axonerve Redis Server, a GET request can fit in a single packet, so it might be able to run up to 150M RPS. But in this test, the performance was limited to 75M RPS, half of 150M. The reason is the IP of FPGA to receive packets from the 100G Ethernet interface, which is placed in the front of the Redis Engine of Axonerve, takes two cycles. Therefore, replacing this IP with an IP that can be processed in a single clock cycle (an IP that can be pipelined in such a way) will give us the capability of 150M RPS.
Measurement results: Latency
Now, let's take a look at the measurement results of the response latency. In both cases, the packets sent and received by the GET command of the redis benchmark client are mirrored to TestCenter by the switch, and the delay time is calculated by comparing the difference between the request and response timestamps.
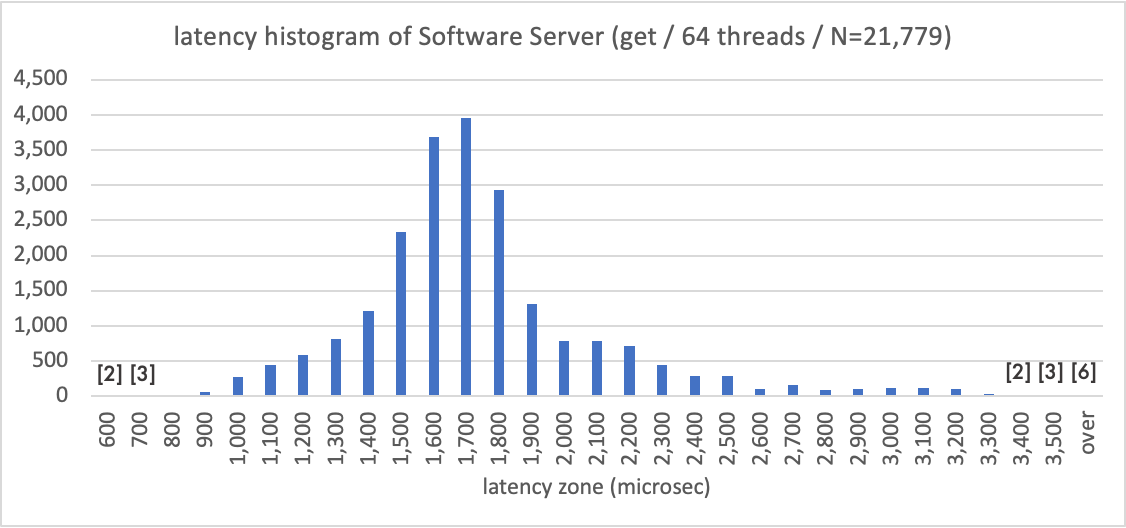
Shown below is the distribution of the latency of the Software Server. As you can see, there is a neat distribution around the 1,700 microsecond range. "Over" means the number of trials with a latency greater than 3,500 microseconds. Well, the trend is a typical trend of software processing, isn't it?
The following graph shows a histogram of Axonerve Server, with microseconds on the horizontal axis. Axonerve server responds in around 3 microseconds, which is also an order of magnitude faster than the Software Server.
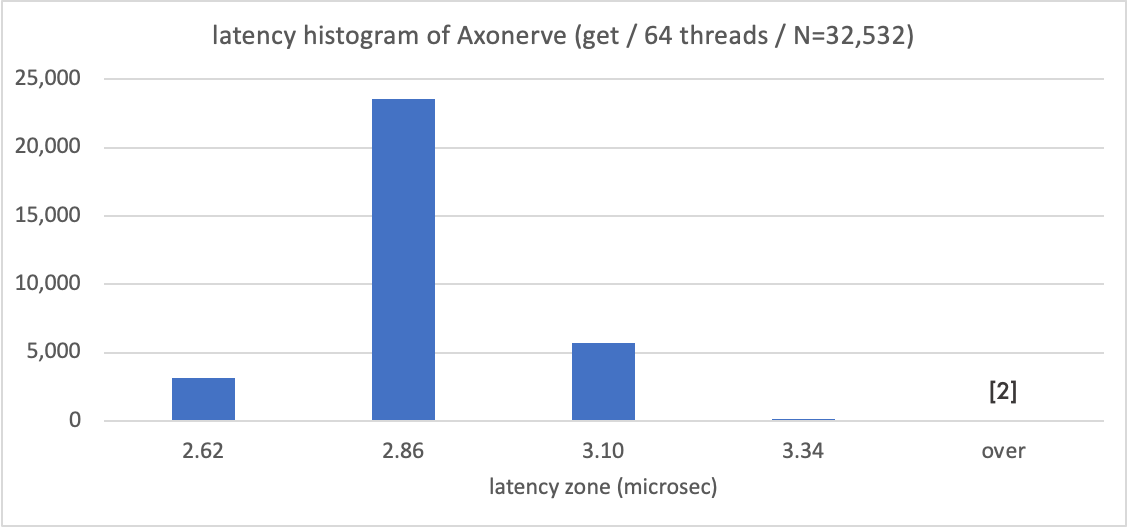
600 nanoseconds, 1/5 of the 3 microsecond delay, is the response time of the Axonerve IP core itself.
Since TestCenter is interacting with Axonerve on 10G Ether across the switch, the response time could be reduced if all connections were 100G.
There are just four visible timestamps in TestCenter. Since the FPGA is processing one request per 150MHz clock, these 0.14 microseconds differences must have been injected in the 10G Ether path accidentally. It is a typical hardware behavior.
Notice (3):
The "over" on the right side of the graph for Axonerve Server means losses, which occurred in only two of the 33,000 requests. Currently, Axonerve Server does not handle lost attempts.
Conclusion
In this experiment, we evaluated the capability of a prototype Redis Server as an application example of Axonerve's key search engine. Compared to the common Redis Server on Linux hosts, the Axonerve Server showed superior performance in the following two points:
- Constant response time of 3 microseconds
(560 times faster than Software server's 1,700 microseconds) - Maximum throughput of 75M RPS
(290 times higher than Software server's 0.26M RPS)
Hundreds times difference is important, but guaranteed scalability is also important, as follows.
- The response delay is constant regardless of the query volume, or the load
- Throughput increases completely linearly with the load
Single server for better performance
In the session "Redis at Lyft: 1,000 Instances" (June 2018) at RedisConf 2018, it was reported that Lyft has achieved 25M RPS with a 64 node cluster. It's been a while since the announcement, but I hope you can feel the magnitude of the 75M RPS figure of the prototype Axonerve Server.
This is the result of the single server with single PCIe card plugged in. In comparison to the AWS 64 nodes that are operated with Auto Scaling, it is quite a simple configuration.
Of course, the current Axonerve Server is an "accelerator" that does not support all Redis instructions. However, for users with such a large scale of processing, it would be worthwhile.
It may also be valuable for the operation team of a small but rapidly growing service. Of course, the operation of such a cluster configuration of large-scale servers could be "nothing" for you, but the accumulation of operational know-how, such as node failure handling and recovery processing are quite burdensome in a cluster system. I think it is worthwhile in that aspect as well.
Proposals for new fields
Since the response latency is extremely short and constant, Axonerve can be applied to areas where the best effort response has been useless. That is, the Open Source tools and middleware that many engineers are familiar with can be used to develop applications that require (somewhat strict) latency guarantees, such as 5G-related applications.
Of course, those who are seriously developing 5G-related low-latency applications will continue to develop anything from scratch, regardless of the compatibility with available software.
But I think wider the entrance is to this area, the better things can happen. I'd like to lightly say something like, "We have an on-premises Redis server with orders of magnitude higher performance and microsecond latency guarantees. Anyone have any interesting ideas?"
When you say, "We have a great FPGA IP core, we have a driver, would you like to try it?", probably you get less people to touch it, right?
In closing
For now, we are still in the "I built a prototype Redis server and tried it out" stage. Currently, the implementation is focused on a few functions that especially requires speed, such as SET/GET, MSET/MGET.
In general, the accelerator is required to accelerate the specific functions. There is no need to cover all functions exhaustively, and we would rather develop it with people who say, "If this function is available, I use it" or "If it can do this, I start marketing".
If you are interested in Key Value search acceleration for 150M RPS, please contact us at info@axonerve.com.
P.S.
Axonerve was originally designed as an FPGA IP core, and the performance number of 150 MSPS was given at the design stage. In today's FPGA development, if the simulator says it works, it almost certainly works. So the developers assume that 150 MSPS will be achieved without any need for actual measurement. Of course, it would be nice if all the users would consider it that way, but I guess people with more software backgrounds would be looking for solutions for large-scale key search demands. For those people, it's not enough to say, "Here's an FPGA that does 150M searches". Unless someone has tried it out, or has measured it, it's hard to trust it (unless you can see the code).
The Xilinx App Store is a service that anyone can try to run benchmarking software on Docker. For large application developers looking for an accelerator, it is a good environment.