この記事
筆者はここしばらく、FPGAベースのキー探索エンジンを独自開発しているスタートアップ、Axonerve のお手伝いをしています。この Axonerve エンジンを使った Redis Server の試作バージョンが出来たので、一般的なソフトウェアベースの Redis Server との比較を行いました。
主な報告ポイント
- スループットにおいて 75M requests/sec までリニアにスケールすることを確認した
- 遅延において 3 マイクロ秒(ほぼ固定)で動作することを確認した
以下に今回のテスト内容を説明しますが、とにかく先に結果を見たい人は、Axonerve Server (with TestCenter)まで飛ばしてください。その後また戻ってきて順に細かいところを押さえて頂ければ良いかと。
なお、同じものが Xilinx App Store に掲載されており、すぐに試せる状態にあります。後述の FPGA カードは必要ですが、それが無くともソフトウェアなどを確認することはできます。
Axonerve について
Axonerve はFPGAベースのキー探索エンジンを独自開発しているスタートアップです。いわゆる KVS - つまり Key となるビット列を与えると、そのキーに結びつけられた Value を返すもの、と考えて下さい。Key, Value ともに FPGA 上のメモリ上に蓄積するモデルで、高性能・低遅延を追求しています。
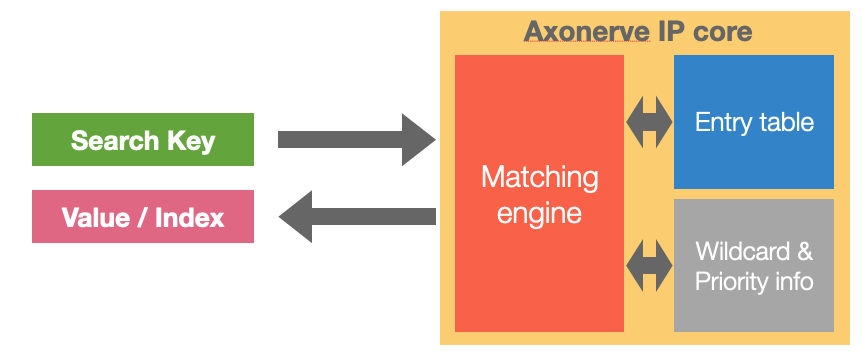
簡単に性能数字を並べておきます。
- キー長: 144 / 288 / 576 / 1152 bits
- エントリ数: 1M (最大)
- 遅延: 120 ナノ秒(固定)
- スループット: 150 MSPS(*1) (clock 150MHz の場合)
なお機能的にはキーに対する完全マッチだけでなく、「このフィールドがこうだったら他のビットは何でもOK」といったワイルドカードが指定できます。OpenFlow のマッチパターンを見慣れている人は想像しやすいかと。詳しくは web を見て下さい。
今回のテストは HBM を利用してエントリ数を拡大したバージョンで行いました。キー長は 288bit、エントリ数 64M、遅延 600ナノ秒となります。36 バイトのキー(String型)が6400万件登録できる超高速 Redis サーバを開発した、と考えてください。
*1) 本稿では FPGA 上のキー探索エンジンとしての能力は、TCAM の処理能力などでよく使われる MSPS - Million Searches Per Sec で表現しています。Redis Server としての処理能力の説明には、この分野の人により馴染みがあるであろう M RPS - Million Requests Per Sec を用います。
計測環境
今回は以下のような機器構成でテストしました。
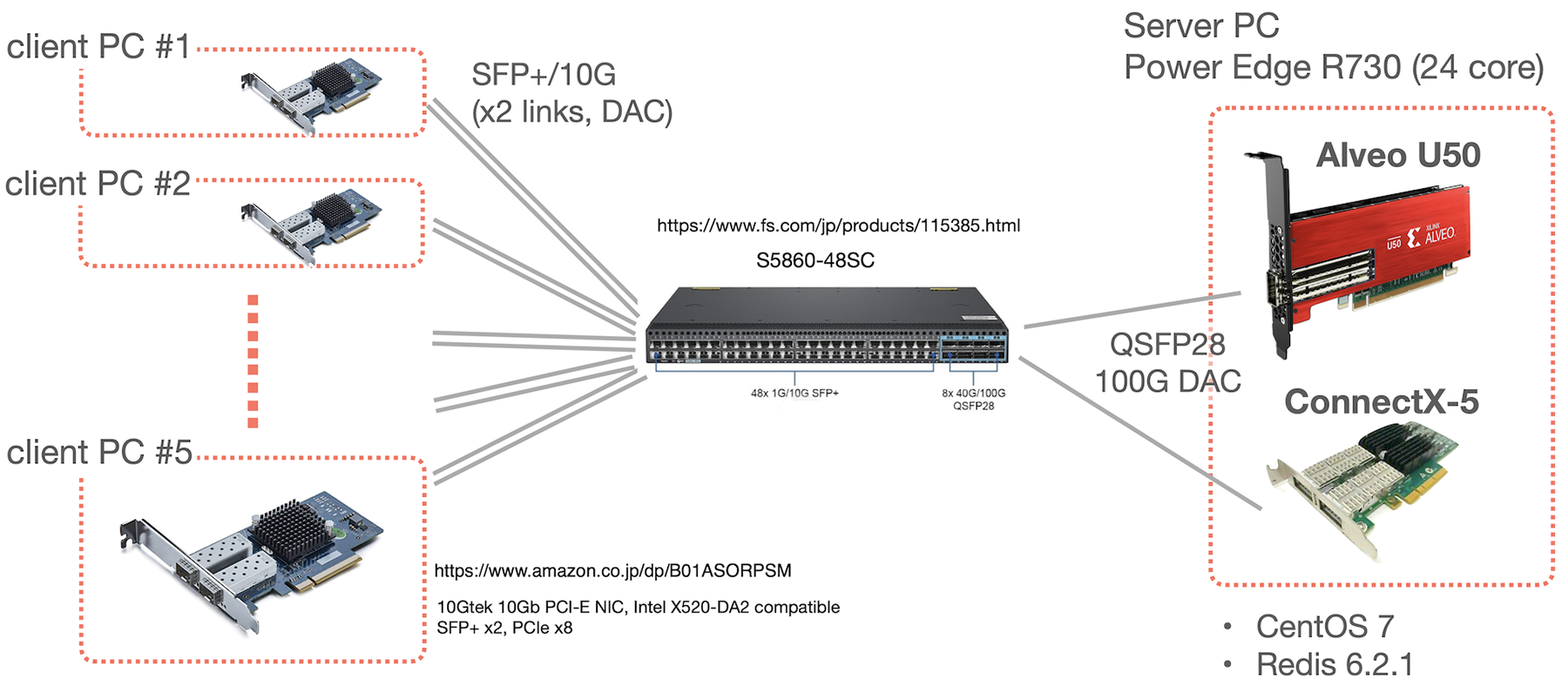
つまり複数台のクライアント PC から、FPGA 上の Axonerve Redis サーバ(以後、Axonerve Server と呼ぶ)と、普通の Linux host 上の Redis Server (以後、Software Server と呼ぶ)に redis-benchmark を使ってスループットと遅延の状況を比較します。
Axonerve Server
Axonerve Server は Xilinx 社の FPGA カード Alveo U50 上で動作します。SET/GETなどの処理リクエストは FPGA カード内で完結し、ホストとなっている PC はまったく関与しません。U50 は 100G Ethernet のインタフェイスをカード上に積んでおり、Redis のリクエストはこのインタフェイスを通して処理します。
Software Server / Server PC
比較対象となる Software Server は Alveo のホストでもある PC 上で動作させています。このPCには 100G Ethernet カード(Mellanox ConnectX-5)が積まれており、Software Server 宛ての Redis のリクエストはこの ConnectX-5 を通して処理します。
モデルは DELL PowerEdge R730です。性能に関係しそうな情報を出しておきます。
- Xeon E5-2650 v4 (12 cores, 2.2GHz) x2
- CentOS 7
- Redis version 6.2.1
- AOF, RDB はともに disable (永続化機能なし)
- io-threads は 7、io-threads-do-reads は no (実験的に得た最適値)で設定
(AOF/RDB が enable の場合は io-threads 15 が最適値だった)
Client PC / Network
測定は redis-benchmark を使いました。このツールはコネクション数やスレッド数などいくつかの多重度に関して設定可能なパラメタがあります。これ以降に Axonerve Server、Software Server それぞれのスループット(requests/sec)や平均遅延が出ますが、それらの数字は両環境それぞれで最良のスループットが得られる多重度設定を試して数字を出しています。ただしパイプライン処理は設定していません。
redis benchmark を実行する Client PC には NEC Express5800/T110j-S (N8100-2798Y, Xeon E-2224 3.4GHz) を 5 台用意しました。全台に 10G SFP+ x2 の NIC を入れています。これらと 100G のサーバは、FS.com の S5860-48SC スイッチで接続しています。単純な L2 スイッチとして設定しています。
Notice (1):
Axonerve Server はテスト時点では TCP に対応させておらず、redis-benchmark を修正して専用の L2 レベルのパケットを raw socket で送受信するようにしています。その意味では完全にフェアな比較にはなっていないことにご留意ください。
(Axonerve としては完全に同条件でテストできることより、基本的な性能が充分に出せていることを確認する方向で今回の試作バージョンを実装しています。この部分の内部処理の詳細に興味のある方は、Xlinx の App Store 上の情報をご覧下さい。)
計測結果:スループット
以下に Axonerve Server の特長が良く現れている結果を、その性質が分かりやすくなるように順を追って示します。
Software Server (with redis-benchmark)
まずベースラインとして redis-benchmark クライアントの台数を増やしたときの Software Server の SET/GET スループットの変化を示します。
$ redis-benchmark -t get -c 64 -n 100000 --threads 64 ...
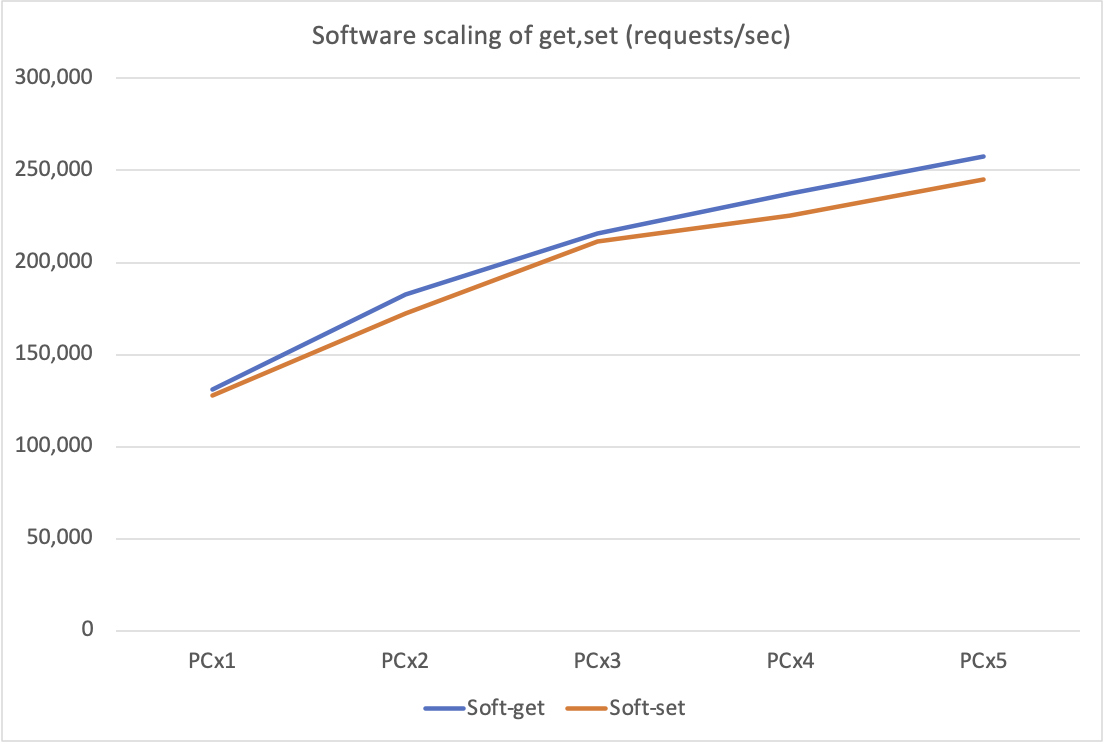
横軸は台数。縦軸は requests/sec です。台数が増えるに従って伸びていっていることが分かります。ただ、その角度に注目してください。徐々に寝ていっていることが窺われます。以下に補助的に近似線を入れたものを示します。
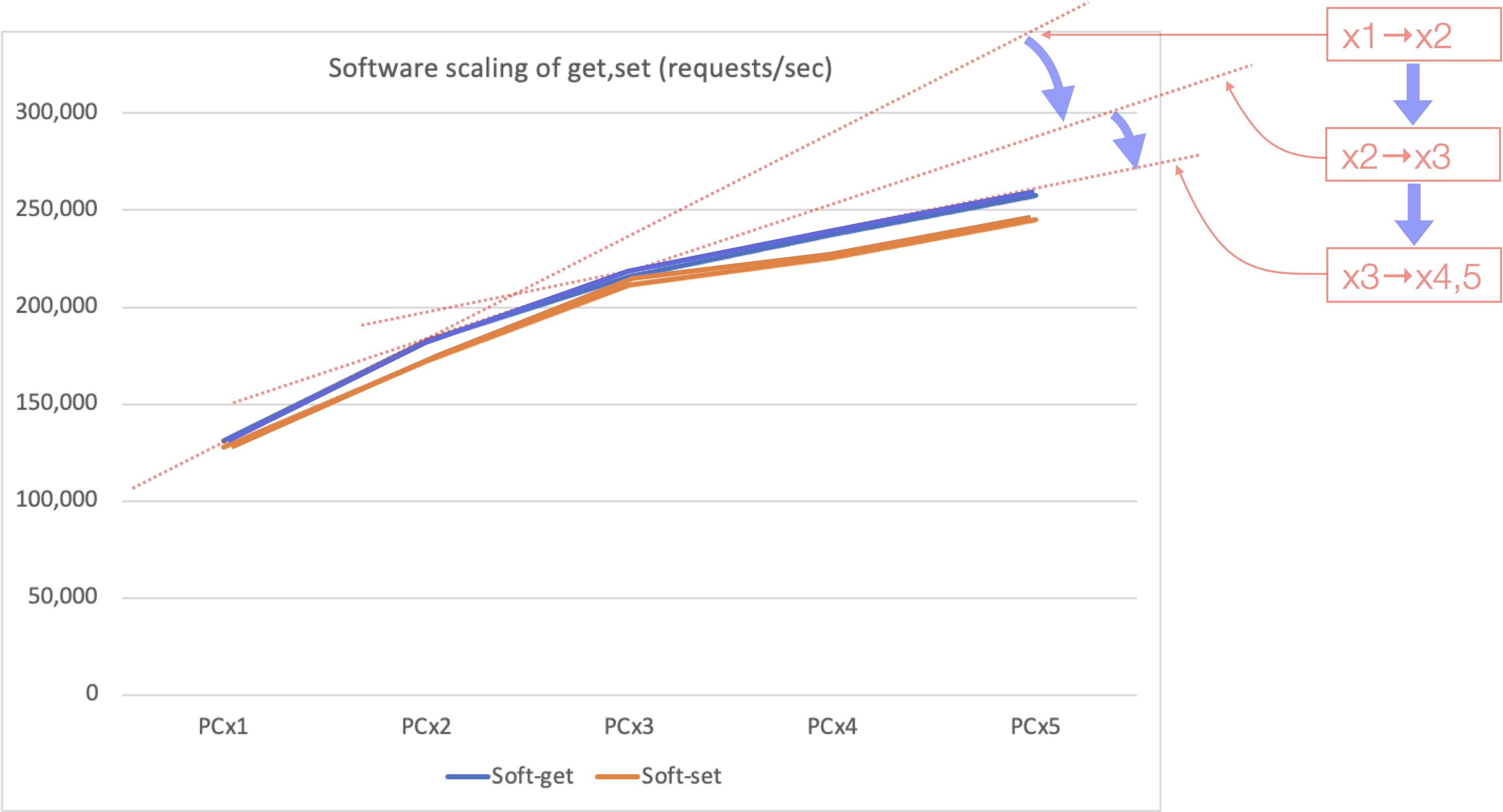
クライアントを徐々に増やしたとき、その伸び具合が鈍化していますね。4台から5台に増やしたときにほぼ変化がなかった原因はよく分かりません。しかしこのとき、サーバのCPU使用率(*2)は PC 1 台で 40%、PC 5 台で 55% に達しています。機材の性能を上げるなり、クライアントの台数を更に増やせばトータルのスループットはまだ上がるでしょうが、しかしこの倍程度で、いずれにしても律速は見えている、という印象です。
*2) top -H が示した main スレッドと io-thread(7つ) の平均値。なお io-thread は先述の通り、これ以上増やしても全体スループットが上がらないことを確認している。
Notice (2):
このテストは「世界最高速の Single Redis server の性能」を出すことを目的としていません。手元の Software Server の性能上限と、今回の実験環境が妥当であることを確認した上で、スケールさせたときのカーブ、つまり傾向を見ることが主目的です。そのつもりで読み進めて下さいましね。
(最大数値という意味では、例えば「マルチスレッド対応が入ったRedis6の確認」(2020/5)で、たむたむさんは AWS の c5.9xlarge を使って SET/GET で 50 万 requests/sec、つまり我々の環境の倍程度まで出ることを示されています。今やれば、もっと大きな数字が出る可能性もあるでしょう。)
Axonerve Server (with redis-benchmark)
次に redis-benchmark クライアントの台数を増やしたときの Axonerve Server の SET/GET スループットの変化を、上の Software Server のグラフに追加する形で示します。
$ redis-benchmark -t get -c 64 -n 4000000 --threads 64 ...
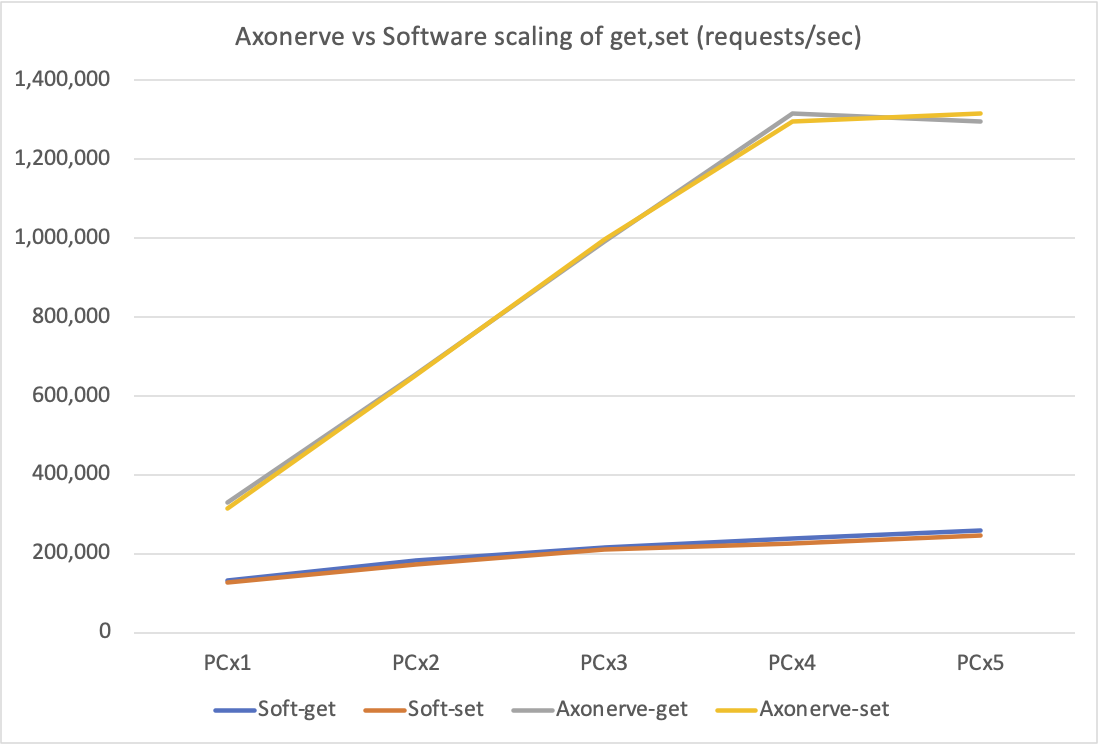
追加された灰色と黄色のラインが Axonerve Server によるものです。クライアントの環境は上記 Software Server のテストと同じです。(ただし Notice (1) に示した通り、redis-benchmark ソフトの低レイヤー部分が異なります)
クライアント 1 台で、そもそものスループットが Software Server の倍ですが、それよりその角度がほぼ 45 度で、クライアント 4 台まで完全にリニアにスケールしていることが目立ちます。ここから、Software Server として「2倍」の性能のものを今回我々が頑張って用意する意味が無いことが分かります。
逆にクライアントが 4 台から 5 台になったときに急に伸びなくなったことが気になりますが、それ自身は Axonerve Server の問題ではないことが次のテストで分かると思います。
Axonerve Server (with TestCenter)
今回用意したクライアント PC 5台ではこれ以上負荷を上げられませんから、Spirent TestCenter (*3)でリクエストパケットを作って投げつけてみました。
*3) ネットワーク負荷試験装置。任意のパケットを生成して指定間隔で送出するなどして処理速度を計測します。先述のスイッチに10G回線x10本で接続して試験しています。
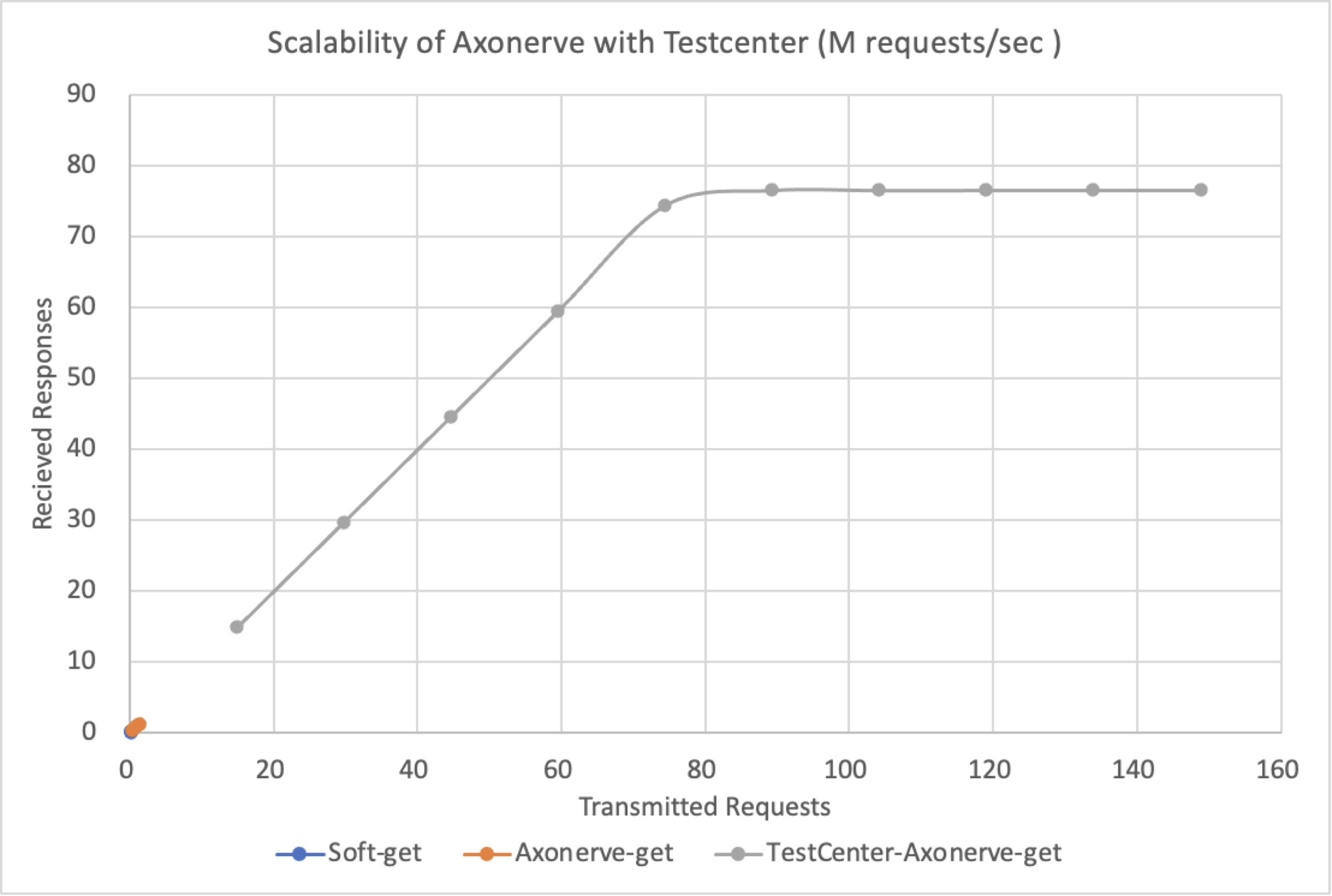
横軸は送出した GET の数、縦軸は受信した応答の数、です。単位はともに Million Requests Per Sec (以後 M RPS)です。先のテスト同様、リクエスト量に対する応答性能は完全に 45度の右肩上がりで 75M RPS までリニアに伸びていることが分かります。
注目すべきはグラフの左下、原点付近です。つまり左下に小さく見えている青とオレンジの線が、上に示していた Software / Axonerve Server の redis benchmark の結果グラフ(に相当する領域)です。つまり redis benchmark を PC 5 台で回したときの最大値が、Software server で約 25 万 = 0.25M RPS、Axonerve Server で約 130 万 = 1.3M RPS だったわけですが、「リクエストを送りつけることさえできれば」まったく桁違いの 75M RPS までリニアに出ていることが確認できました。
なお、送出上限が 150M RPS になっているのは、それが 100G Ethernet のワイヤーレートだからです。そして Alveo U50 に搭載された FPGA のクロックサイクルも 150MHz であり、Axonerve IP core の最大性能も 150 MSPS (Million Searches Per Second) です。また現在の Axonerve Redis Server の実装では GET request は 1 パケットに収まるため、150M RPSまで出そうなものですが、今回のテストではその半分の 75M RPS で頭打ちになりました。原因は今回 Axonerve の Redis Engine の前段に入れた、100G Ethernet インタフェイスからパケットを受信するための IP がその処理に 2 サイクルを要するためです。つまりこの IP を 1 クロックで処理可能なもの(そのようにパイプライン化できる IP )に交換することで 150M RPS の能力が出ると思われます。
計測結果:遅延
続いて応答遅延の計測結果を示します。ともに redis benchmark クライアントのGET コマンドの送受信パケットを、スイッチ側でミラーして TestCenter に受信させ、リクエストと応答のペアをとって両タイムスタンプの差分から遅延時間を求めています。
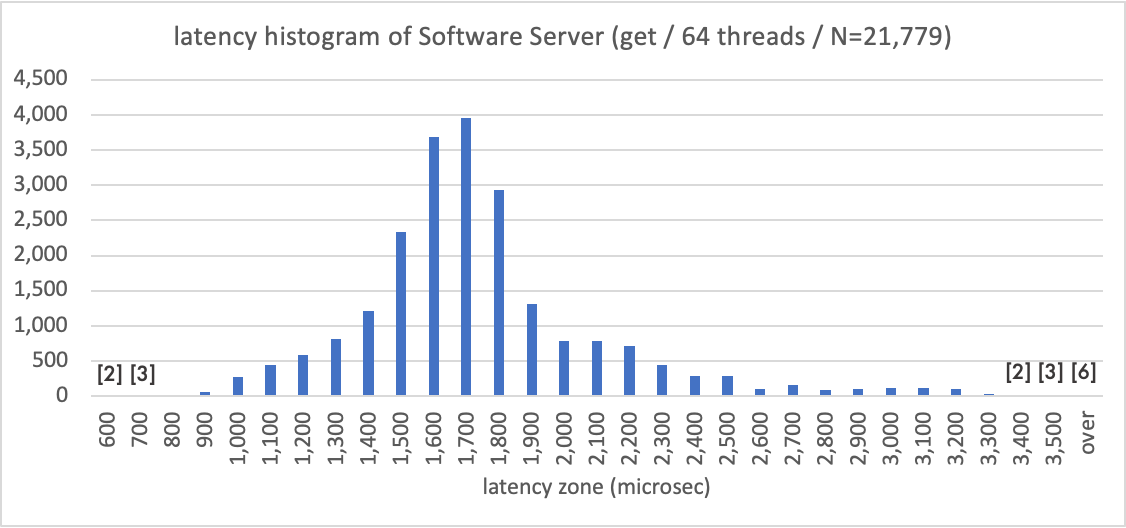
まず Software Server による遅延の分布を示します。横軸に応答遅延をとり(単位はマイクロ秒)、100マイクロ秒幅で全 2.2 万試行のカウントを取ってヒストグラムとしました。1,700マイクロ秒の前後に、きれいな分布が見えます。カウントが一桁になったものには実数を記しています。over としたのは 3,500マイクロ秒より大きな遅延となったものの合計です。まあ、ソフトウェア処理らしい傾向が出ていますね。
対して下のグラフが Axonerve Server のもので、同様に横軸にマイクロ秒を取ってヒストグラムとしています。これもまた Software Server に対して桁違いに高速な 3 マイクロ秒前後で返答していることが分かります。
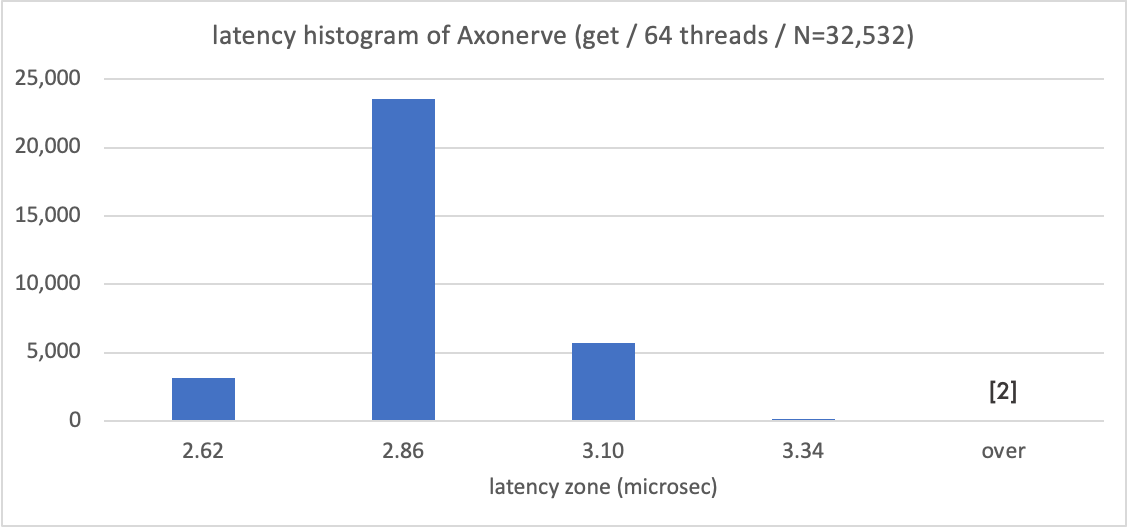
3 マイクロ秒の遅延のうち 1/5 にあたる 600ナノ秒が Axonerve IP core 自体の応答時間です。TestCenter は 10G Ether でスイッチ越しに Axonerve と対話していますから、全て 100G 接続にするとまだ詰められると思われます。
なお TestCenter のタイムスタンプとしてはこの見えている 4 種類しか現れませんでした。FPGA は 150MHz のクロック刻みで 1 リクエストを処理しているはずなので、もうこれは計測経路である 10G Ether パスを通過するなかで乗った(僅か 0.14マイクロ秒の)ブレでしょうね。さすがハードウェア、です。
Notice (3):
Axonerve Server のグラフ右端の over はロストを意味しており、これが 3.3 万試行のうち 2 つだけ発生しました。現時点の Axonerve Server は ロスト対応を行っていません。
まとめ
今回、Axonerve がそのキー探索エンジンの応用例として試作した Redis Server の能力評価をしました。一般的な Linux ホスト上の Software Redis Server に対して、Axonerve Server は以下の 2 点において優れた性能を示しました。
- 応答遅延がほぼ 3 マイクロ秒
(Software server の 1,700マイクロ秒に対して560倍) - 最大スループットが 75M RPS
(Software server の 0.26M RPS に対して290倍)
何百倍、という値も重要ですが以下の性質、つまりスケーラビリティが保証されていることも重要です。
- 問い合わせ量、つまり負荷の高低によらず応答遅延は固定
- 負荷に対してスループットは完全にリニアに上がる
シングルサーバによる性能向上
Redisconf 18 でのセッション 「Redis at Lyft: 1,000 Instances」 (2018/6) で、Lyft が 64 ノードのクラスタを組んで 25M RPS を実現していることが報告されています。発表から日が経っていますが、今回の試作 Axonerve Server の 75M RPS という数字の大きさが感じられるでしょうか。Auto Scaling まで入れて運用する AWS 64 ノードに対して、PCIe カード一枚差しただけのシングルサーバでこの数字、です。
もちろん現在の Axonerve Server は Redis の全命令に対応していない「アクセラレータ」な状態ですが、しかしこのような大規模処理を抱えているユーザにとってはそれだけでも利用価値があると思えます。
小さくとも急激に伸張しているサービスの運用チームにとって、こうした大規模サーバのクラスタ構成運用が「なんでもない」のであれば良いのですが、クラスタ構成でのノード故障対応・復元処理などの運用ノウハウ蓄積は結構な負荷とも想像され、そうした面でも価値があるかと。
新しい領域への提案
また、応答遅延が極端に短く、固定的であることから、いままでの best effort 的な応答では使えなかった領域に適用できそうです。つまり 5G 関連など、遅延保証が(ある程度厳しく)要求されるアプリケーションを開発するのに、多くのエンジニアが慣れ親しんだ Open Source のツール群、ミドルウェアが使えるようになるのです。
もちろん本気で 5G 関連の低遅延必須のことをやっている人たちは既存ソフトウェアとの親和性なんて関係無くガリガリと何でも作り込んでいくんだよ、という話もあるでしょうが、このあたりの入り口は広い方が良いことが起きそうに思います。「桁違いに高性能で、マイクロ秒単位の遅延保証のあるオンプレミス Redis サーバあります、何か面白いこと思いついた人いませんか」みたいに軽く呼び掛けたいじゃないですか。(凄い FPGA IP コアあります、ドライバありますが試しませんか、では触って貰える人の数がぐっと減っちゃいますよね、、)
おわりに
今回は「Redis サーバを試作したので試してみた」状態です。現在は SET/GET, MSET/MGET など幾つかの特に高速性が要求されそうな処理に絞り込んで実装した状態です。アクセラレータに要求されるのは特定機能の加速であってすべての機能を網羅的にカバーしていないのは問題ないでしょうが、むしろ今「これがあるなら使う」「これができたら売る」という人と一緒に開発したい、という状況です。
もし 150M RPS の Key Value search アクセラレーションに興味が湧かれましたら、是非 info@axonerve.com までご連絡ください。
おまけ
Axonerve は元々 FPGA IP core として作られており、150 MSPS という性能数字は設計段階で出ています。いまどきの FPGA は設計段階で動くと言えばほぼ間違い無く動きますから、開発側としては実測するまでもなく 150 MSPS 出るものと考えています。もちろんその流儀で検討してくれるユーザばかりなら良いのですが、大規模キーサーチ需要についてソリューションを探すのはもっとソフトウェア寄りのバックグラウンドをもった人たちだろうなと想像します。そういう人たちにただポンと「150M search 出る FPGA ですよ」だけではダメですよね。手元で試すか、誰かが実測した結果が無いと、またそのコードが見えていないと今ひとつ信用できないでしょう。
Xilinx App Store は誰でも簡単に Docker ベースでベンチマークソフトを動かすところまで到達できるサービスです。アクセラレータを探している大規模アプリケーション開発者にとって、この現在の状況はとても良いですね。